Why some screening hits are a PAIN
Posted: 22 June 2021 | Dr Matthew Lloyd (University of Bath) | No comments yet
A major challenge during high-throughput and fragment screening is the potential for identifying ‘frequent hitters’ – compounds that affect unrelated targets. Matthew Lloyd from the University of Bath explains why these hits can arise during drug discovery and how machine learning could be the answer to identifying these compounds.
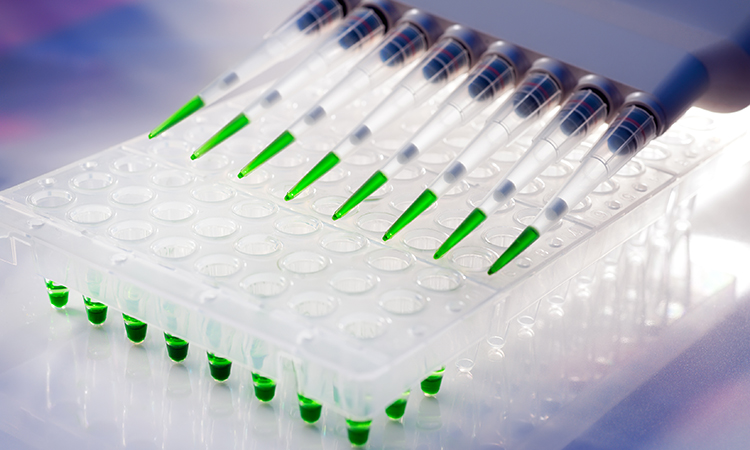
High-throughput screening (HTS) is a common method used in drug discovery (Figure 1). In a typical campaign, an isolated protein is incubated with a diverse library of compounds, drug-like molecules, natural products or other potential drugs and their ability to modify a protein function (such as enzymatic activity) is measured. Screening libraries typically contain many thousands or even millions of compounds. An advantage of utilising HTS is that it can be used to identify novel chemical scaffolds that mediate their effects by several different pharmacological mechanisms.1 A related approach is fragment screening, in which a smaller library of lower molecular weight compounds (typically <300 Da.) are screened by biophysical methods such as surface plasmon resonance (SPR), isothermal calorimetry (ITC) and X-ray crystallography to identify fragments which bind to the target.2 Such fragments typically bind very weakly, but they can be optimised into highly potent and selective compounds.2 These screening approaches are widely recognised as valuable drug discovery strategies.
Related topics
Assays, Drug Discovery, High-Throughput Screening (HTS), Nuclear Magnetic Resonance (NMR), Screening, Small Molecules, X-ray Crystallography
Related organisations
Beckman Coulter, Horizon Discovery, Merck, X-Chem
Related people
Laurianne David, Matthew Matlock